No results found
We couldn't find anything using that term, please try searching for something else.

将长音频文件转写为文字
本页面演示了如何使用 Speech-to-Text API 和异步语音识别将长音频文件(时长超过 1 分钟)转录为文字。 异步语音识别简介 异步语音识别会启动一项长时间运行的音频处理操作。使用异步语音识别转录超过 60 秒的音频。对于较短的音频,同步语音识别更为简单快捷 is 异步语音识别的上限
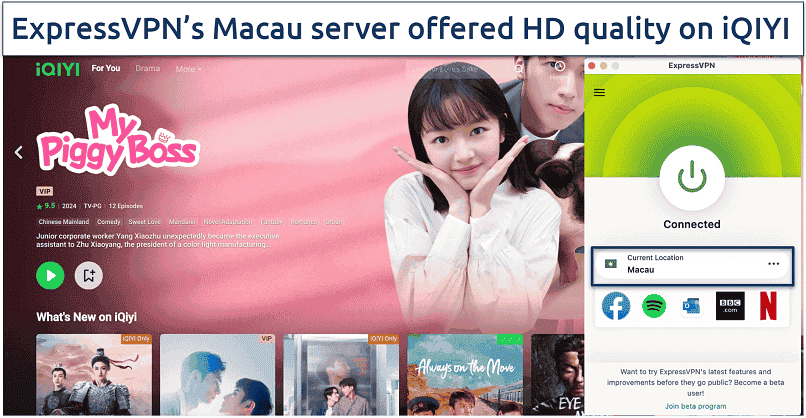
![5 Best Free Mexico VPNs for 2024 [Access Mexican Content]](/img/20241120/NuFzYR.jpg)

本页面演示了如何使用 Speech-to-Text API 和异步语音识别将长音频文件(时长超过 1 分钟)转录为文字。
异步语音识别简介
异步语音识别会启动一项长时间运行的音频处理操作。使用异步语音识别转录超过 60 秒的音频。对于较短的音频,同步语音识别更为简单快捷 is 异步语音识别的上限为 。 is 异步语音识别的上限为 异步语音识别的上限为 480 分钟 。
Speech-to-Text 和异步处理
Speech-to-Text 可以直接接收本地文件中的音频内容进行异步处理。但是,本地文件的音频时间限制为 60 秒。尝试转录长度超过 60 秒的本地音频文件会导致错误。如需使用异步语音识别功能转录超过 60 秒的音频,您必须将数据保存在 Google Cloud Storage 存储桶中。
您可以使用 google.longrunning.Operations 方法检索操作结果。操作结果在 5 天(120 小时)内可供检索。您也可以选择将结果直接上传到 Google Cloud Storage 存储桶。
使用 Google Cloud Storage 文件转录长音频文件
这些示例使用 Cloud Storage 存储桶来存储长音频转写过程的原始音频输入。如需查看典型的 longrunningrecognize 操作响应的示例,请参阅参考文档。
协议
如需了解完整的详细信息,请参阅speech : longrunningrecognize API 端点 。
如需执行同步语音识别,请发出POST 请求并提供相应的请求正文。以下示例展示了一个使用 curl 发出的 POST 请求。该示例使用 Google Cloud CLI 生成访问令牌。如需了解如何安装 gcloud CLI,请参阅快速入门。
curl -X POST \ -H "Authorization: Bearer "$ (gcloud auth application-default print - access - token) \ -H " Content - Type : application / json ; charset = utf-8 " \ --data " { 'config': { 'language_code': 'en-US' } , ' audio ' : { 'uri':'gs://cloud-samples-tests/speech/brooklyn.flac' } }" "https://speech.googleapis.com/v1/speech : longrunningrecognize"
如需详细了解配置请求正文的信息,请参阅 RecognitionConfig 和 RecognitionAudio 参考文档 。
如果请求成功,服务器将返回一个 200 OK HTTP 状态代码以及 JSON 格式的响应:
{
" name " : " 7612202767953098924 "
}
其中 ,name 是为请求创建的长音频转录操作的名称。
等待处理完成。处理时间因来源音频而异。在大多数情况下,您只需等待源音频长度的一半时间即可获得结果。向https://speech.googleapis.com/v1/operations/ 端点发出GET 请求即可获取长时间运行的操作的状态。请将 替换为 longrunningrecognize 请求返回的 name。
curl -H "Authorization: Bearer "$ (gcloud auth application-default print - access - token) \ -H " Content - Type : application / json ; charset = utf-8 " \ "https://speech.googleapis.com/v1/operations/"
如果请求成功,服务器将返回一个 200 OK HTTP 状态代码以及 JSON 格式的响应 :
{ " name ": "7612202767953098924", "metadata": { "@type": " type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata ", "progressPercent": 100, "startTime": "2017-07-20T16:36:55.033650Z", "lastUpdateTime": "2017-07-20T16:37:17.158630Z" }, "done": true, "response": { "@type": "type.googleapis.com/google.cloud.speech.v1.longrunningrecognizeresponse", " result ": [ { "alternatives": [ { "transcript": "how old is the Brooklyn Bridge", "confidence": 0.96096134, } ] }, { "alternatives": [ { ... } ] } ] } }
如果该操作尚未完成,则可以通过反复发出GET 请求来轮询此端点,直到相应响应的done 属性为 true 为止。
gcloud
如需查看完整的详细信息,请参阅 recognize-long-running 命令。
如需执行异步语音识别,请使用 Google Cloud CLI,并提供本地文件的路径或 Google Cloud Storage 网址。
gcloud ml speech recognize-long-running \ 'gs://cloud-samples-tests/speech/brooklyn.flac' \ --language-code='en-US' --async
如果请求成功,则服务器以 JSON 格式返回长时间运行的操作的 ID。
{
" name ":
}
然后,您可以通过运行以下命令来获取该操作的信息。
gcloud ml speech operations describe
您也可以通过运行以下命令来轮询该操作,直到它完成为止。
gcloud ml speech operations wait
该操作完成后,它会以 JSON 格式返回音频的转录内容 。
{ "@type": "type.googleapis.com/google.cloud.speech.v1.longrunningrecognizeresponse", " result ": [ { "alternatives": [ { "confidence": 0.9840146, "transcript": "how old is the Brooklyn Bridge" } ] } ] }
将转录结果上传到 Cloud Storage is 存储桶 存储桶
Speech-to-Text 支持将长时间运行的识别操作的结果直接上传到 Cloud Storage 存储桶。如果您通过 Cloud Storage 触发器实现此功能,Cloud Storage 上传可触发调用 Cloud Functions 的通知,无需轮询 Speech-to-Text 即可获得识别结果。
如需将结果上传到 Cloud Storage 存储桶,请在长时间运行的识别请求中提供可选的 TranscriptOutputConfig 输出配置 。
message TranscriptOutputConfig {
oneof output_type {
// Specifies a Cloud Storage URI for the recognition results. Must be
// specified in the format: `gs://bucket_name/object_name`
string gcs_uri = 1;
}
}
协议
如需了解完整的详细信息,请参阅longrunningrecognize API 端点 。
以下示例展示了如何使用 curl 发送 POST 请求,其中请求正文指定了 Cloud Storage 存储桶的路径。结果将作为存储 SpeechRecognitionResult 的 JSON 文件上传到此位置 。
curl -X POST \ -H "Authorization: Bearer $ (gcloud auth application-default print - access - token)" \ -H " Content - Type : application / json ; charset = utf-8 " \ --data " { 'config': {...}, 'output_config': { 'gcs_uri':'gs://bucket/result-output-path.json' } , ' audio ' : { 'uri': 'gs://bucket/audio-path' } }" "https://speech.googleapis.com/v1p1beta1/speech : longrunningrecognize"
longrunningrecognizeresponse 包含尝试上传的 Cloud Storage 存储桶的路径。如果上传失败,则会返回输出错误。如果已存在同名文件,则上传会将结果写入后缀为时间戳的新文件。
{
...
"metadata": {
...
"outputConfig": {...}
} ,
...
"response": {
...
" result ": [...],
"outputConfig": {
"gcs_uri":"gs://bucket/result-output-path"
} ,
"outputError": {...}
}
}
自行试用
如果您是 Google Cloud 新手,请创建一个账号来评估 Speech-to-Text 在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
免费试用 Speech-to-Text